
My Journey From a Warehouse Floor to the Microsoft Store and Everywhere in Between
PC Workman is a Windows system monitor with a fully offline AI assistant, built solo, in public, on a 2014 laptop between warehouse and welding shifts. This ...
Updated just now · 20 articles from HackerNoon
PC Workman is a Windows system monitor with a fully offline AI assistant, built solo, in public, on a 2014 laptop between warehouse and welding shifts. This ...

The article argues that AI is transforming rather than replacing technical jobs. It contends that developers who combine AI with strong engineering fundament...
Drawing on six implementations of the same data grid, the article argues that the most durable UI pattern is separating behavior from presentation through he...

Replacing a background-job system is risky because the jobs do real work. The fix is to never rewrite the jobs: wrap each one in a thin consumer that only ha...

Code review was built for a world where the supply of code was bounded by how fast a person could write it. That world is over, and the tools built to keep p...

The article outlines the first stage of building an AI-powered dream analysis system. Rather than relying on symbolic dream dictionaries, it proposes a conte...
The result is that a casual, conversational request produces the kind of output that would normally require a carefully engineered prompt. Less setup, less f...
AI agents go beyond chatbots: they perceive a task, reason through clinical and payer rules, take an action inside the EHR or payer system, then verify the r...

Benchmarks tell you what a model can do. They don't tell you whether you can trust what it says. Those have always been two separate questions, and for a lon...
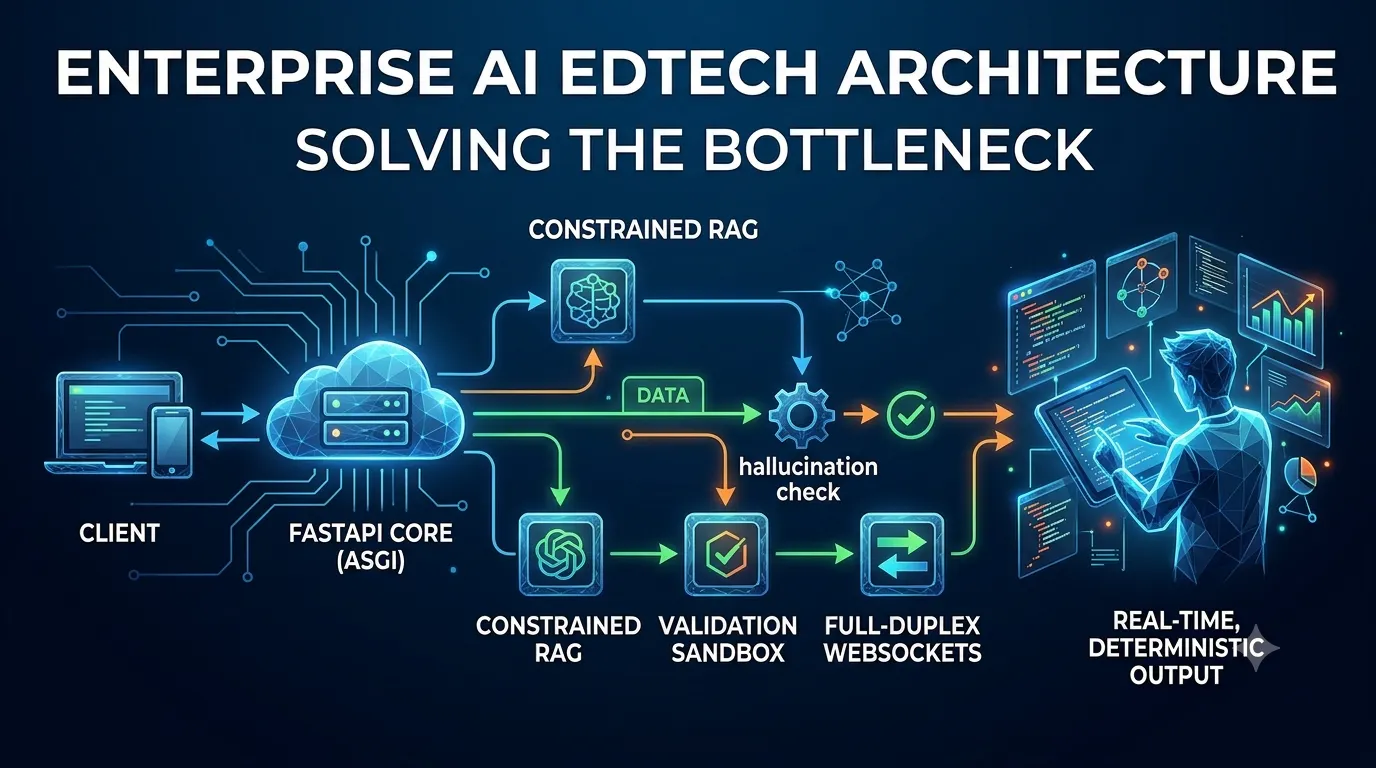
Traditional HTTP architecture breaks down under the heavy concurrent load required by real-time AI tutors. This article provides a comprehensive software eng...
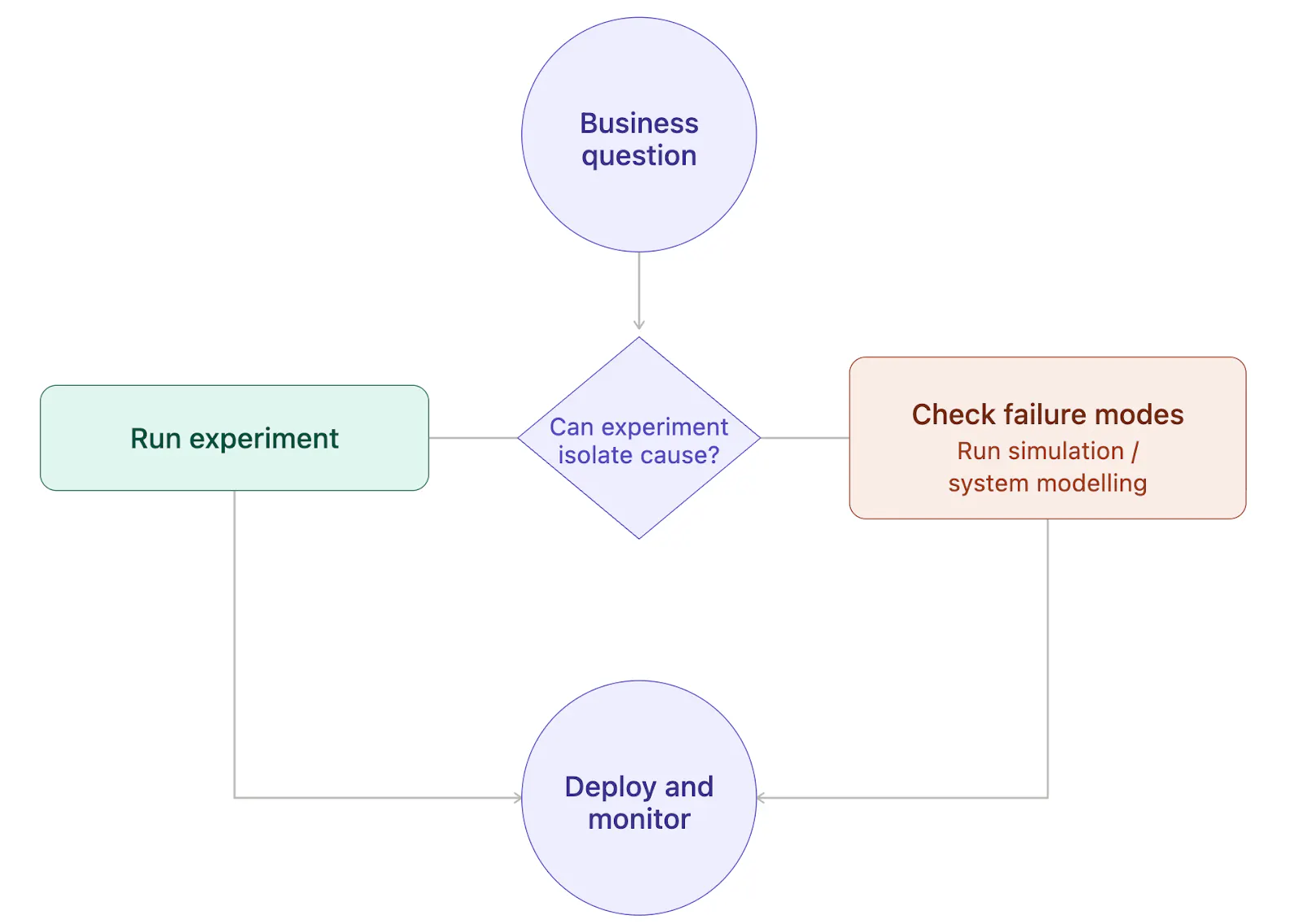
The article argues that successful experimentation depends on more than statistical rigor. It introduces a framework built around four common failure modes, ...

Active scanning tools like nmap can easily crash fragile, legacy industrial hardware. MEA (Modbus Exposure Analyzer) solves this by passively monitoring raw ...
